DataScience_Examples
All about DataSince, DataEngineering and ComputerScience
View the Project on GitHub datainsightat/DataScience_Examples
dbt (Data Build Tool)
- dbt: https://www.getdbt.com/
- Snowflake: https://ns18238.us-east-2.aws.snowflakecomputing.com
- Jinja: https://jinja.palletsprojects.com/en/3.1.x/
- Udemy: https://www.udemy.com/course/complete-dbt-data-build-tool-bootcamp-zero-to-hero-learn-dbt
Demo Model
https://github.com/datainsightat/DataScience_Examples/tree/main/de/dbt
Admin
Install
pip install virtualenv
virtualenv venv
source venv\Scripts\activate
dbt commands
Check Structure
dbt compile
Create Models
dbt run
dbt run --select src_hosts+
Create Snapshots
dbt snapshot
Run Tests
dbt test
Install Packages
Get packages fromhttps://hub.getdbt.com/ and reference it in packages.yml
dbt deps
Generate Documentation
dbt docs generate
dbt docs serve

Data Maturity Model
Data Collection > Data Wrangling > Data Integration > BI and Analytics > Artificial Intelligence
Data Integration
Write data from staging area to database.
ETL vs ELT (Extract, Transform, Load)
- Data Warehouse: Source > Extract > Transform > Load
- Data Lakehouse: Soruce > Extract > Load > Transform
Data Storage
Data Warehouse
A central repository of integrated data from one or more disparate sources. It is used to store structured data.

Data Lake
Storage of unstructured data like Images and text files.
Data Lakehouse
Data management like in a data warehouse, but data is stored cheap datalakes
SCDs Slowly Changing Dimensions
| Type | Desctiption |
|---|---|
| 0 | Not updating the DWH when a dimension changes |
| 1 | Overwrite original data |
| 2 | Add new row |
| 3 | Add new attribute |
CTE Common Table Expression
-- STEP 1
with raw_listings as (
-- STEP 2
select * from [source] [listings]
)
-- STEP 3
select * ftom raw_listings
Data Stack
SMP Warehouses (Symmetric Multi Procecessing)
Each processor is trated equally and runs in parallel with one another. The workload is evenly distributed when processing the program. Each processor shares the same resources. A single computer with multuple CPU cores.
This architecture can only scale vertically.
MPP Cloud Warehouse (Multi Parallel Processing)
Master node and compute nodes. Each processor has its own dedicated resources. Many computers work together.
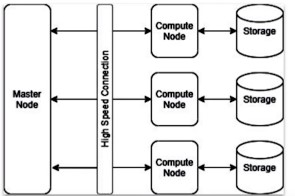
Decoupling of Data and Storage
Comopute nodes are shut down, if not needed. Data persists.
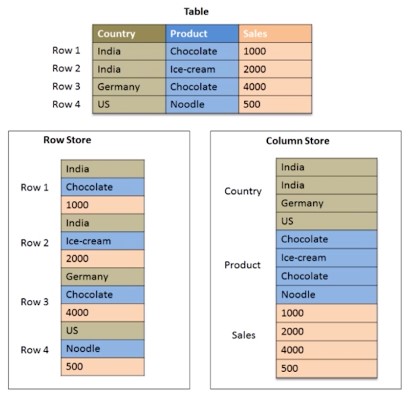
Column Oriented Databases
Row oriented databases are good in reading and writing data, but not efficient for analytical workloads.
Modern Data Stack
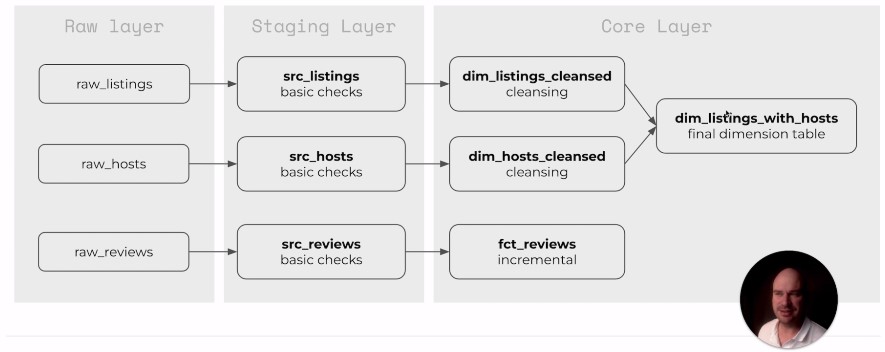
dbt Structures
Materializations
| Type | Use | Don’t Use |
|---|---|---|
| View | lightweight representation | Date often used |
| Table | Data often used | Single-use models, Incremental tables |
| Incremental | Fact tables, Appends | Update historical records |
| Ephemeral | Alias data | Read model several times |
Seeds and Sources
- Seeds are local files that you upload to the dwh
- Sources are abstraction layers on th top of your input tables </a>
Seeds
Copy csv file in ‘seeds’ folder
dbt seed
Sources
Sources are abstractions of tables.
with raw_reviews as (
select * from --AIRBNB.RAW.RAW_REVIEWS
)
Data Freshness
Check, if data is current. Condigure freshness in ‘sources.yml’
sources:
- name: airbnb
schema: raw
tables:
- name: reviews
identifier: raw_reviews
loaded_at_field: date
freshness:
warn_after: {count: 1, period: hour}
error_after: {count: 24, period: hour}
run command
dbt source freshness
Snapshots
Handle type 2 slowly changing dimensions. Example update e-mail address and keep history. dbt adds two dimensions: dbt_valid_from and dbt_valid_to.
| Strategy | How To |
|---|---|
| Timestamp | Unique columns: key and updated_ad |
| Check | Any change in set of columns trigger snapshot |
snapshots/scd_raw_listings.sql
{\% snapshot scd_raw_listings \%}
select * from
{\% endsnapshot \%}
Tests
- There are two types of tests: singular and generic
- Singular tests are SQL queries stored in tests which are expected to return an empty resultset
- Generic tests:
- unique
- not_null
- accepted_values
- relationships
- You can define your own custom generic tests. </a>
Generic Tests
models/schema.yml
version: 2
models:
- name: dim_listings_cleansed
columns:
- name: listing_id
tests:
- unique
- not_null
- name: host_id
tests:
- relationships:
to: ref('dim_hosts_cleaned')
field: host_id
- name: room_type
tests:
- accepted_values:
values: ['Entire home/apt',
'Private room',
'Shared room',
'Hotel room']
Singular Tests
Tests passes, if query returns no values.
test/dim_listings_minimum_nights.sql
select
*
from
where
minimum_nights < 1
limit 10
tests/consistent_crated_at.sql
SELECT
*
FROM
l
INNER JOIN r
USING (listing_id)
WHERE
l.created_at >= r.review_date
Macros
- Nacros are jinja templates created in the macros folder
- There are many built-in macros in DBT
- You can use macros in model definitions and tests
macros/no_null_in_columns.sql
{\% macro no_nulls_in_columns(model) \%}
select
*
from
where
{\% for col in adapter.get_columns_in_relation(model) -\%}
is null or
{\% endfor \%}
false
{\% endmacro \%}
tests/no_nulls_in_dim_listings.sql
dbt test --select dim_listings_cleansed
Custom Generic Tests
macros/positive_value.sql
{\% test positive_value(model,column_name)\%}
select
*
from
where
< 1
{\% endtest \%}
models/schema.yml
- name: minimum_nights
test:
- positive_value
Third-Party Packages
https://hub.getdbt.com/
dbt_utils
packages.yml
packages:
- package: dbt-labs/dbt_utils
version: 0.8.0
models/fct/fct_reviews.sql
with src_reviews as (
select * from
)
select
as review_id,
*
from
src_reviews
where
review_text is not null
{\% if is_incremental() \%}
and review_date > (select max(review_date) from )
{\% endif \%}
$ dbt run --full-refresh --select fct-reviews
Documentation
- Documents can be provided as yaml files, or as markdown files
- dbt ships with a documentation web server
- Customize the landing page with overview.md
- Add assets in special folder
Basic Documentation
models/schema.yml
version: 2
models:
- name: dim_listings_cleansed
description: Cleansed table which contains Airbnb listings.
columns:
- name: listing_id
decription: Primary key fot the listing
Markdown Files
models/docs.md
{\% docs dim_listing_cleansed__minimum_nights \%}
Minmum number of nights required to rent this property.
Keep in mind that old listings might have 'minimum_nights' set
to 0 in the source tables. Our cleansing algorithm updates this
to '1'.
{\% enddocs \%}
models/schema.yml
- name: minimum_nights
description: ''
Overview
Put images in folder “assets”
dbt_project.yml
asset-paths:["assets"]
models/overview.md
{\% docs __overview__ \%}
#Airbnb Pipeline
Hey, welcome to our Airbnb pipeline documentation!
Here is the schema of our input data:

{\% enddocs \%}
Analyses, Hooks and Exposures
Analyses
Queries, without crearting a model
analyses/full_moon_no_sleep.sql
with markt_fullmoon_reviews as (
select * from
)
select
is_full_moon,
review_sentiment,
count(*) as reviews
from
mart_fullmoon_reviews
group by
is_full_moon,
review_sentiment
order by
is_full_moon,
review_sentiment
$ dbt compile
$ less target/compiled/dbtlearn/analyses/full_moon_no_sleep.sql
Hooks
- SQLs that are executed at predefined times.
- Hooks can be configures on the project, subdolder, or model level
- Types:
- on_run_start: Execute at start of dbt
- on_run_end: Execute at end of dbt
- pre-hook: Execute before a model is built
- post-hook: Execute after a model was built
Exposures
Links to external applications.
models/dashboard.yml
version: 2
exposures:
- name: Executive Dashboard
type: dashboard
maturity: low
url: XXX
description: Executive Dashboard
depends_on:
- ref('dim_listings_cleansed')
- ref('mart_fullmoon_reviews')
owner:
name: me
email: me@email.com
Python Models
https://docs.getdbt.com/docs/building-a-dbt-project/building-models/python-models
models/my_python_model.py
def model(dbt, session):
...
return final_df
def model(dbt, session):
# DataFrame representing an upstream model
upstream_model = dbt.ref("upstream_model_name")
# DataFrame representing an upstream source
upstream_source = dbt.source("upstream_source_name", "table_name")
...
models/downstream_model.sql
with upstream_python_model as (
select * from
),
...
Incremental Tables
/loop.sh
#!/bin/bash
clear
echo "#### Set variables ... ####"
START_MONTH=202201
END_MONTH=202212
declare -i periods=$END_MONTH-$START_MONTH
echo $periods
echo "#### Loop ... ####"
# Write new table with first period
declare -i period=$START_MONTH
echo $period
# declare 'model_increment' as:
dbt run --vars '{start_period: '$period',end_period: '$period'}' --full-refresh --select model_increment --target schema
# Append periods, if more than 1 period
if [ $periods > 1 ]
then
for i in $(seq 1 $periods)
do
declare -i period=$START_MONTH+$i
echo $period
dbt run --vars '{start_period: '$period',end_period: '$period'}' --select model_increment --target schema
done
fi
Test
Project
Python Connector
Sharepoint
sharepointAPI.py
import requests
import xmltodict
from requests_ntlm2 import HttpNtlmAuth
import pandas as pd
import os
import re
import logging
logging.basicConfig(level=logging.INFO)
logging.info('Module sharepoint loaded')
class SharepointSource(object):
def __init__(self,site_url,user,password,db_name=None, db_user=None, db_pw=None): #,listener_table=None
self.site_url = site_url
self.api_url = "{0}_api/web/".format(self.site_url)
self.user = user
self.authntlm = HttpNtlmAuth(user,password)
def get_list_filenames(self,page_url):
sp_url = "{0}GetFolderByServerRelativeUrl('{1}')/files".format(self.api_url,page_url) #/Files?$select=Name
response = requests.get(sp_url,auth=self.authntlm)
data = xmltodict.parse(response.text)
file_count = len(data["feed"]["entry"])
files = []
for i in range(file_count):
if (file_count == 0):
files.append([data["feed"]["entry"]["content"]["m:properties"]["d:Name"],data["feed"]["entry"]["content"]["m:properties"]["d:TimeLastModified"]["#text"]])
else:
files.append([data["feed"]["entry"][i]["content"]["m:properties"]["d:Name"],data["feed"]["entry"][i]["content"]["m:properties"]["d:TimeLastModified"]["#text"]]) #[i]
return(files)
app.py
import os
import pandas as pd
import numpy as np
import re
import yaml
from datetime import datetime
from dotenv import load_dotenv
load_dotenv()
import logging
logging.basicConfig(level=logging.INFO)
from sharepointAPI import sharepoint
###############
# Load Config #
###############
with open(os.path.dirname(__file__)+'/src_config.yaml', 'r') as f:
config = yaml.safe_load(f)
################
# Extract Data #
################
def extract():
site_url=config['site_url']['upload']
sp_folder = config['folder']['datenbasis']
sp = sharepoint.SharepointSource(site_url,user=os.getenv(config['sharepoint']['user_env']),password=os.getenv(config['sharepoint']['pw_env']))
name = sp.get_latest_filename(page_url=sp_folder)[0]
logging.info(name)
raw_data = sp.get_file(page_url=sp_folder,file=name)
data = pd.read_excel(raw_data,sheet_name=0,engine='openpyxl')
logging.debug('extract done ...')
return data
data_l = extract()
logging.debug(data_l.head())
src_config.yaml
#####################
# Paths and Folders #
#####################
sharepoint :
user_env : 'user' # Set the value of this variable in your .env file
pw_env : 'pw' # Set the value of this variable in your .env file