DataScience_Examples
All about DataSince, DataEngineering and ComputerScience
View the Project on GitHub datainsightat/DataScience_Examples
Data Engineer Exam
Data Engineer Exam Guide
Google Cloud Documentation
Medium Blog
Practice Exam
Ressources
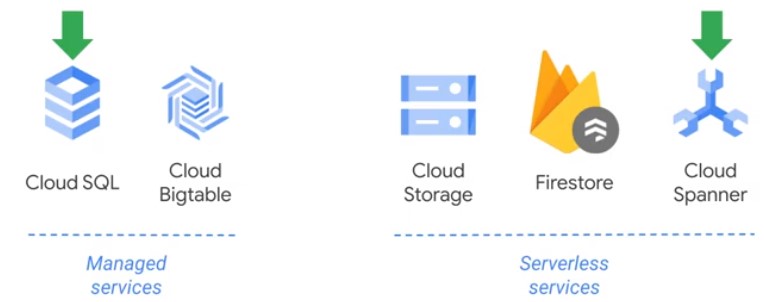
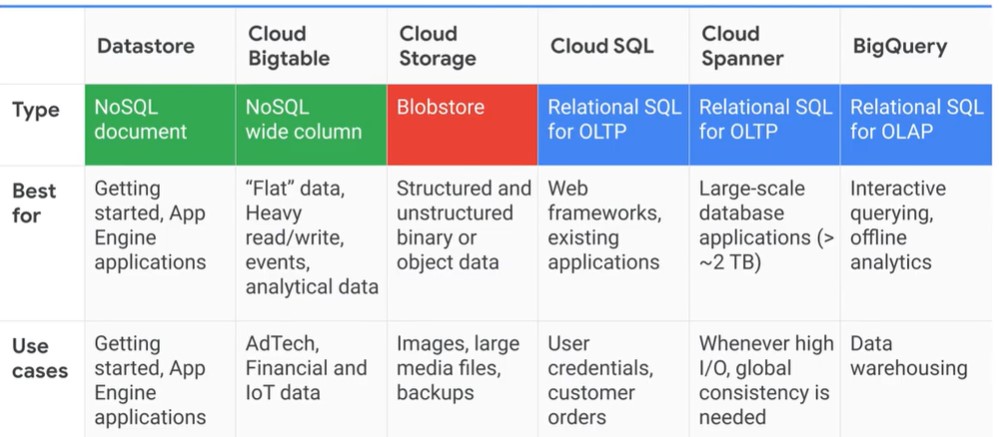
Storage and Database Documentation
| Topic | Description | Link |
|---|---|---|
| Disks | https://cloud.google.com/compute/docs/disks/ https://cloud.google.com/bigtable/docs/choosing-ssd-hdd | |
| Cloud Storage | World-wide storage and retrieval of any amount of data at any time | https://cloud.google.com/storage/docs/ |
| Cloud Memorystore | Fully manage in-memory data store service. | https://cloud.google.com/memorystore/docs/redis/ |
| Cloud SQL | MySQL and PostgreSQL database service | https://cloud.google.com/sql/docs/ |
| Datastore | NoSQL document and database service | https://cloud.google.com/datastore/docs/ |
| Firestore | Store mobile and web app data at global scale | https://cloud.google.com/firestore/docs |
| Firebase REaltime Database | Store and sync data in real Time | https://firebase.google.com/docs/database/ |
| Cloud BigTable | NoSQL wide-column database service. | https://cloud.google.com/bigtable/docs/ |
| Cloud Spanner | Mission-critical, scalable, relational database service | https://cloud.google.com/spanner/docs/ |
Data Analytics
| Topic | Description | Link |
|---|---|---|
| BigQuery | A full managed, high scalable data warehouse with built-in ML | https://cloud.google.com/bigquery/docs/ |
| Dataproc | Managed Spark and Hadoop service | https://cloud.google.com/dataproc/docs/ |
| Dataflow | Real-time batch and stream data processing | https://cloud.google.com/dataflow/docs/ |
| Datalab | Explore, analyze and visualize large datasets | https://cloud.google.com/datalab/docs/ |
| Dataprep by Trifacta | Cloud data service to explore, clean and prepare data for analysis | https://cloud.google.com/datalab/docs/ |
| Pub/Sub | Ingest event streams from anywhere at any scale | https://cloud.google.com/pubsub/docs/ |
| Google Data Studio | Tell great data stories to support better business desicisions | https://marketingplatform.google.com/about/data-studio/ |
| Cloud Composer | A fully managed workflow orchestration service built on Apache Airflow | https://cloud.google.com/composer/docs/ |
Machine Learning Documentation
| Topic | Description | Link |
|---|---|---|
| AI Platform | Build superior models and deploy them into production | https://cloud.google.com/ml-engine/docs |
| Cloud TPU | Train and run ML models faster than ever | https://cloud.google.com/automl/docs/ |
| AutoML | Easily train high-quality, custom ML models | https://cloud.google.com/automl/docs/ |
| Cloud Natural Language API | Derive insights from unstructured text | |
| Speech-to-Text | Speech-to-text conversion powered by ML | |
| Cloud Translation | Dynamically translate between languages | |
| Text-to-Speech | Text-to-speech conversion powered by ML | |
| Dialogflow Enterprise Edition | Create conversational experiences across devices and platforms | |
| Cloud Vision | Derive insight from images powered by ML | |
| Video Intelligence | Extract metadata from videos |
Infrastructure Documentation
| Topic | Description | Link |
|---|---|---|
| Google Cloud’s operations suite (Stackdriver) | Monitoring and management for services, containers, applications and infrastructure | |
| Cloud Monitoring | Monitoring for applicationson Google Cloud and AWS | |
| Cloud Logging | Logging for applications on Google Cloud and AWS | |
| Error Reporting | Identifies and helps you understand application errors | |
| Cloud Trace | Find performance bottlenecks in production | |
| Cloud Debugger | Investigate code behaviour in production | |
| Cloud Profiler | Continuous CPU and heap profiling to improve performance and reduce costs | |
| Transparent Service Level Indicators | Monitor Google Cloud services and their effects on your workloads | |
| Cloud Deployment Manager | Manage cloud resources with simple templates | |
| Cloud Console | Google Cloud’s integrated management console | |
| Cloud Shell | Command-line management form any browser |
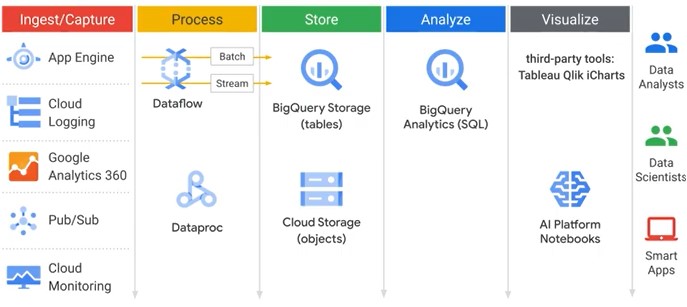
Data Processing Systems
Designing and building
Data Processing Anatomy
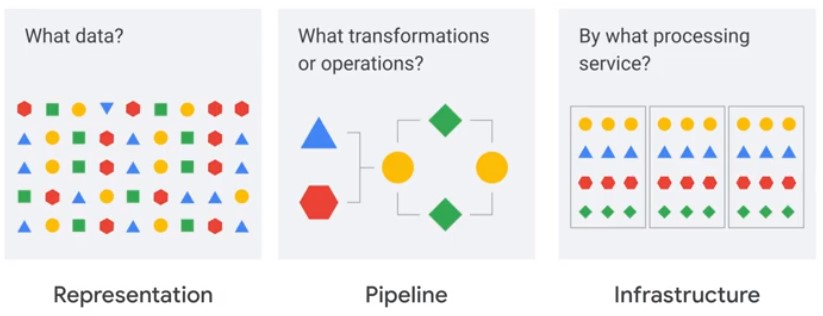
A view of data engineering on Google Cloud
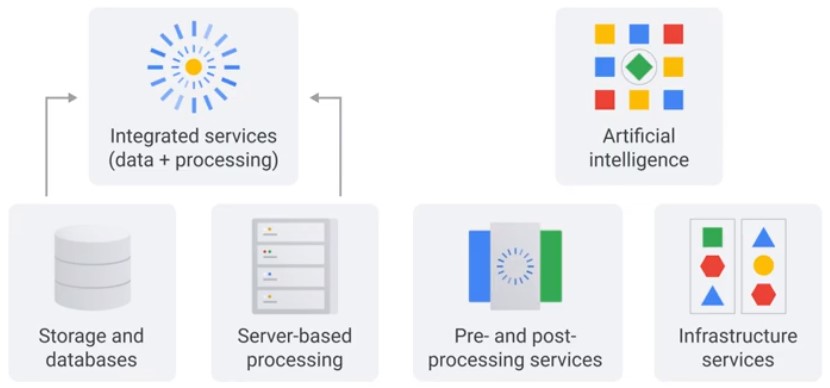
Storage and Databases
Processing

Data Processing Services
Combines storage and compute.

Data Abstractions
| Service | Data Abstraction | Compute Abstraction |
|---|---|---|
| Dataproc, Spark | RDD | DAG |
| Bigquery | Table | Query |
| Dataflow | PCollection | Pipeline |
Artificial Intelligence
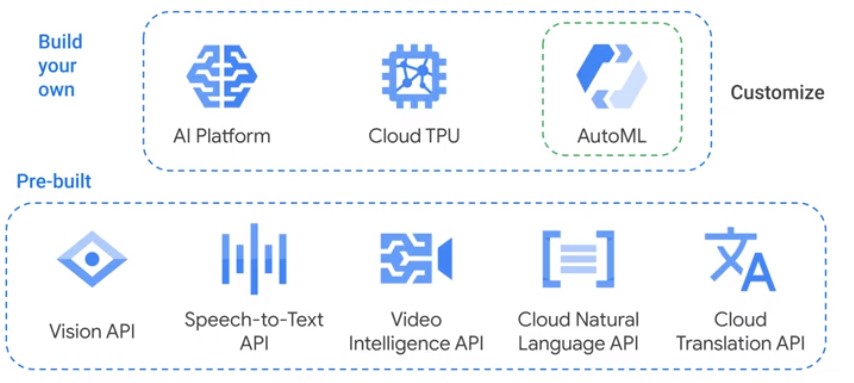
Pre- and Postpcocessing Services

Infrastructure Services
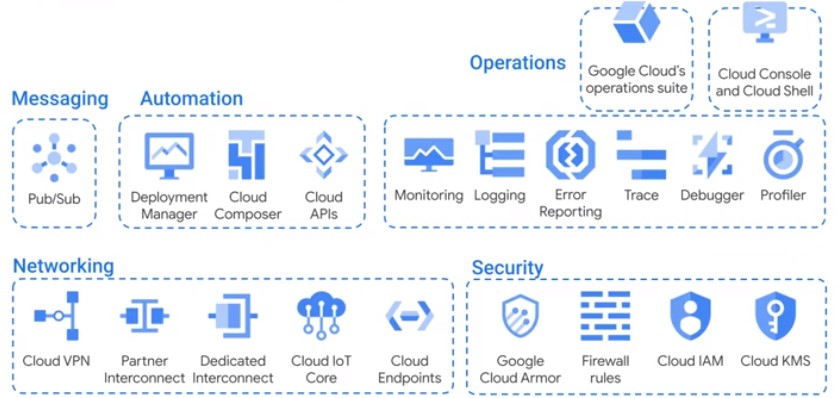
Design Flexible Data Representations
| Storage | Type | Stored in |
|---|---|---|
| Cloud Storage | Object | Bucket |
| Datastore | Property | Entity > Kind |
| Cloud SQL | Values | Rows and Columns > Table > Database |
| Cloud Spanner | Values | Rows and Columns > Tables > Database |
Data in Files and Data in Transit

Standard SQL Data Types
| Data type | Value |
|---|---|
| string | variable-length (unicode) character |
| int64 | 64-bit integer |
| float64 | Double-precision decimal values |
| bool | true or false |
| array | ordered list of zero or more elements |
| struct | container of ordered fields |
| timestamp | represents an absolutej point in time |
BigQuery Datasets, Tables and Jobs
- Project > Users and datasets
- Limit access to datasets and jobs
- Manage billing
- Dataset > Tables and views
- Access Control Lists
- Applied to all tables in the dataset
- Table > Collection of columns
- Columnar storage
- Views are virtual tables
- Tables can be external
- Job > Potentially long-running action
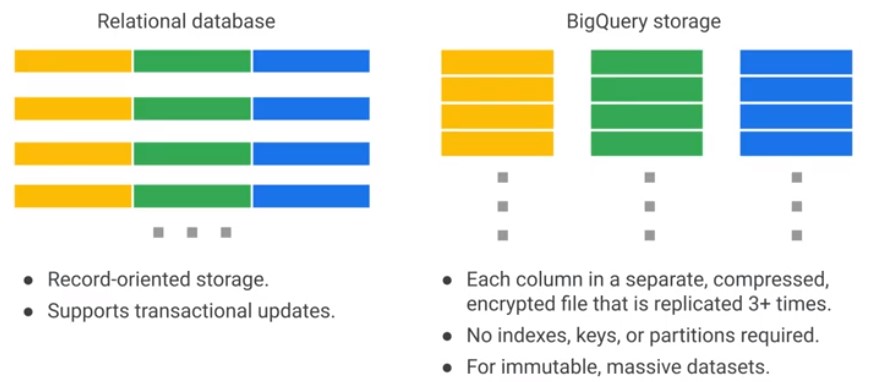
BigQuery is Columnar
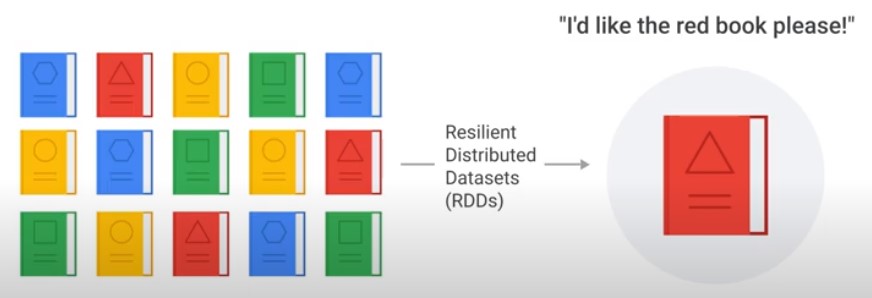
Spark hides Complexity in RDDs
RDDs hide complexity and allow making decisions on your behald. Manages: Location, Partition, Replication, Recovery, Pipelining …
Dataflow
PCollections
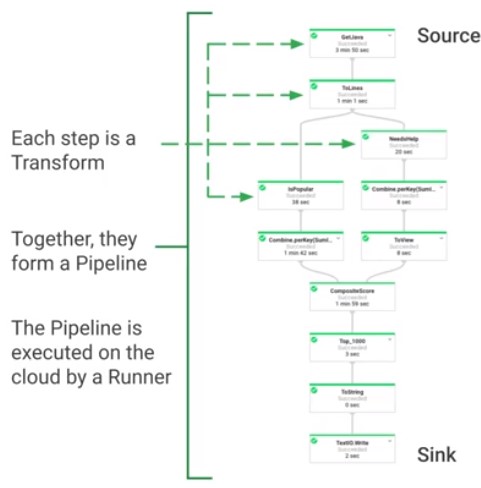
- Each step is a transformation
- All transformations are a pipeline
- Each step is elastically scaled
- Each Transform is applied on a PCollection
- The result of an apply() is another PCollection
Batch and stream processing
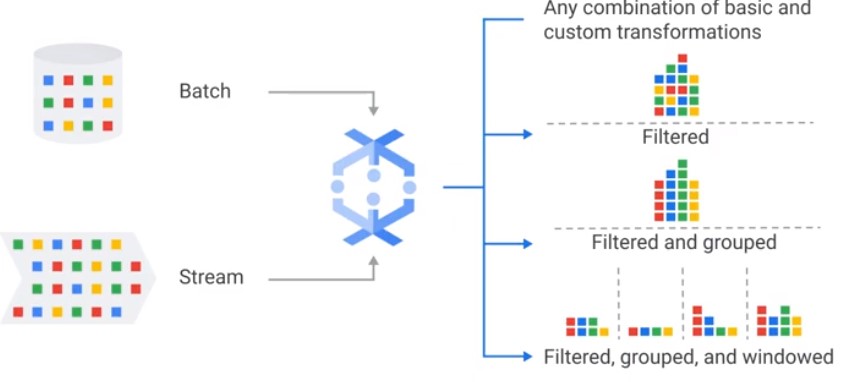
Bounded va Unbounded data. Dataflow uses windows to use streaming data. PCollections are not compatible with RDDs.
Tensorflow
Opensource code for machine learning.
Design Data Pipelines
Dataproc
- Cluster node options: Single node, Standard, High availability
- Benefits: Hadoop, Automated cluster management, Fast cluster resize
- HDFS: Use Cloud Storage for stateless solution
- HBASE: Use Cloud Bigtable for stateless solution
- Objective: Shut down the cluster, Restart per job
- Data storage: Dont’t use hdfs
- Cloud storage: Match you data locatoin with the compute location
Spark
Spark uses a DAG to process data. It executes commands only, if told to do so = “lazy evaluation” (oppostite “eager execution).
Dataproc can augment BigQuery
projectId = <your-project-id>
sql = "
select
n.year,
n.month,
n.day,
n.weight_pounds
from
`bigquery-public-data.samples.natality` as n
order by
n.year
limit 50"
print "Running query ..."
data = qbq.read_sql.gb1(sql,projectId=projectId)
data[:5]
Extract data from BiqQuery using Dataproc and let Spark do the analysis.
Open Source Software
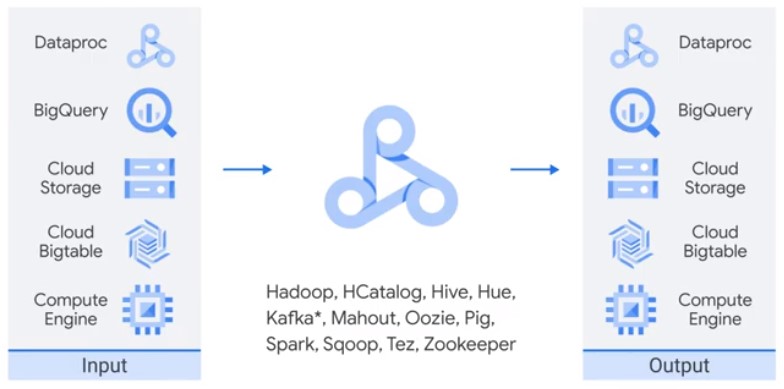
Initialization Actions
- Optional executable scripts
- Allow you to install additional components
- Provide common initialization actions on Github
Cluster Properties
- Allow you to modify properties in common configuration files like core-site.xml
- Remove the need to manually change property files
- Specified by file_prefix:property=value
Dataflow
- Java, or Python
- Based on Apache Beam
- Parallel tasks
- Same Code does stream and batch
- Input from many sources
- Put code inside servlet, deploy it to App engine
- Side inputs
- User dataflow users to limit access to Dataflow ressources
Pipelines

Operations
| Operation | Action |
|---|---|
| ParDo | Allows for parallel processing |
| Map | 1:1 relationship between input and output in Python |
| FlatMap | Non 1:1 relationships |
| .apply(ParDo) | Java for Map and FlatMap |
| GroupBy | Shuffle |
| GroupByKey | Explicit Shuffle |
| Combine | Aggregate values |
Pipelines are often organized in Map and Reduce sequences.
Templates
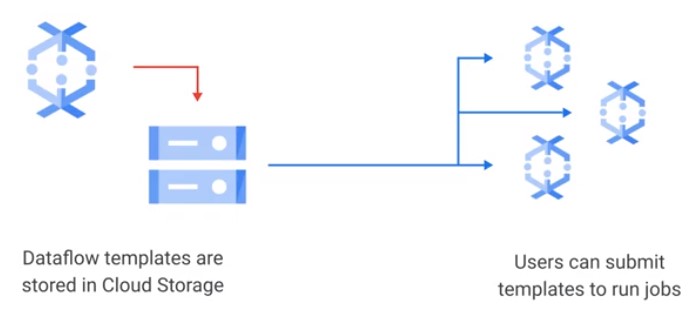
Separation for work and better ressource allocation.
BigQuery
- Near real-time analysis
- NoOps
- Pay for use
- Date storage is inexpensive and durable
- Queries charged on amount of data processed
- Immutable audit logs
- Iteractive analysis
- SQL query language
- Many ways to ingest, transform, load and export data
- Nested and repeated fields
- UDFs in JavaScript
- Structured data
- Frontend does analysis
- Backend does storage
- Datawarehouse solution
- Access control: Project, dataset
Solutions
Separate compute and storage enables serverless execution.
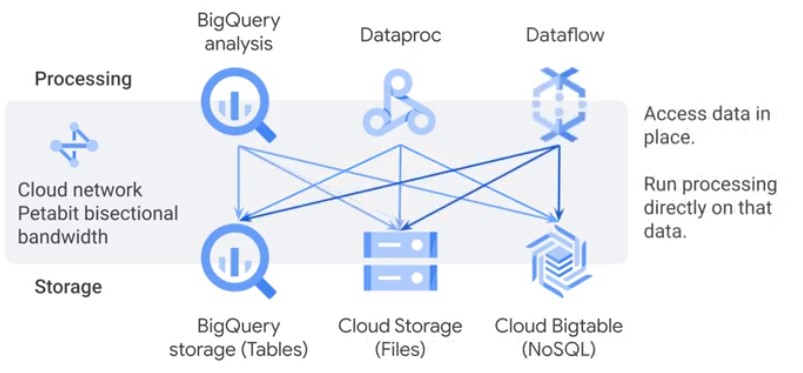
Design Data Processing Infrastructure
Data Ingestion
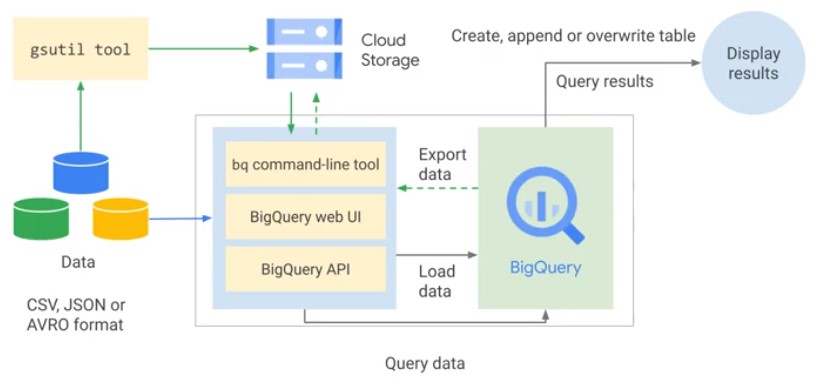
Load data into BigQuery
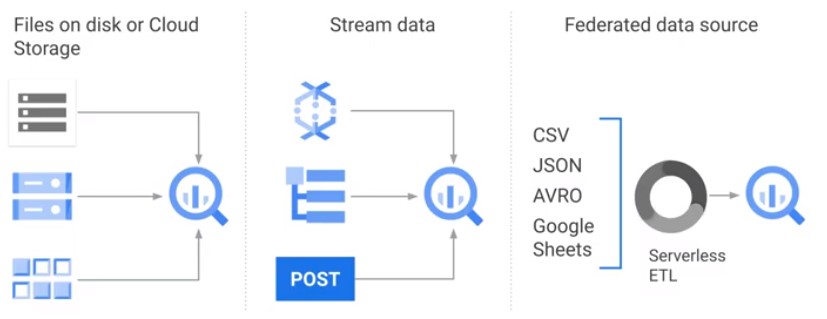
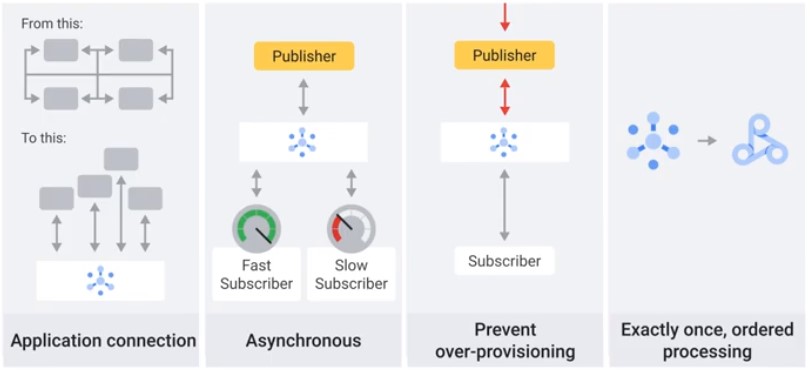
PubSub
- Serverless global message queue
- Asynchronous: publisher never waits, a subscriber can get the message
- At-least-onve deliver guarantee
- Push subscription and pull subscription
- 100s of ms – fast </a>
Pub/Sub holds messages up to 7 days.
| Ingest | Processing | Analysis |
|---|---|---|
| Pub/Sub | Dataflow | BigQuery |
Exam Guide Review
Storage
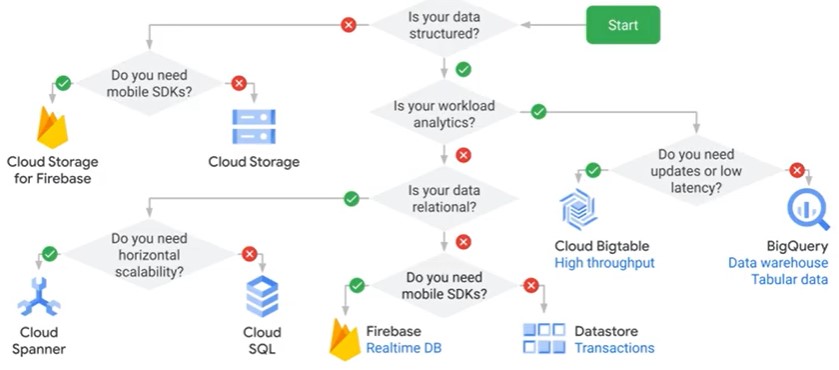
Selecting the appropriate storage technologies
- Mapping storage systems to business requirements
- Data modeling
- Tradeoffs involving latency, thoughput and transactions
- Distributed sytems
- Schema design
Be familiar with the common use cases and qualities of the different storage options. Each storage system or database is optimized for different things - some are best at automatically updating the data for transactions. Some are optimized for speed of data retrieval but not for updates or changes. Some are very fast and inexpensive for simple retrieval but slow for complex queries.
Pipelines
Designing data pipelines
- Data publishing and visualization
- Batch and streaming
- Online (interactive) vs batch predictions
- Job automation and orchestration
An important element in designing the data processing pipeline starts with selecting the appropriate service or collection of services.
All Platform Notebooks, Google Data Studion, BigQuery all have interactive interfaces. Do you know when to use each?
Processing Infrastructure
Designing a data processing solution
- Choice of infrastructure
- System availability and fault tolerance
- use of distributed systems
- Capacity planning
- Hybrid cloud and edge computing
- Architecture options
- At least once, in-order, and exactly once event planning
Pub/Sub and Dataflow together provide once, in-order, processing and possibly delayed or repeated streaming data.
Be familiar with the common assemblies of services and how they are often used together: Dataflow, Dataproc, BigQuery, Cloud Storage and Pub/Sub.
Migration
Migrating data warehousing and data processing
- Awareness of current state and how to migrate design to a future state
- Migrating from on-premise to cloud
- Validating a migration
Technologically, Dataproc is superior to Open Source Hadoop and Dataflow is superior to Dataproc. However, this does not mean that the most advanced technology is always the best solution. You need to consider the business requirements. The client might want to first migrate from the data center to the cloud. Make sure everything is working (validate it). And only after they are confident with that solution, to consider improving and modernizing.
Building and Operationalizing Data Processing Systems
Building Dataprocessing Systems
ACID - Consistency
BASE - Availability
In Cloud Datastore there are just two APIs provide a strongly consistent view for reading entity values and indexes: lookup by key, ancestor query.
Storage Options
Cloud Storage
Cluster node options
Access
Features
- Versioning
- Encryption options: Google, CMEK, CSEK
- Lifecycles
- Change storage class
- Streaming
- Data transfer / synchronization
- Storeage Transfer Service
- JSON and XML APIs
Best Practices
Cloud SQL
Familiar
Not Supported
Flexible pricing
Connect from anywhere
Fast
Google Security
Cloud Bigtable
Properties
- High throughput data
- Millisecond latency, NoSQL
- Access is designed to optimize for a range of Row Key prefixes
Important Features
- Schema design and time-series support
- Access control
- Performance Design
- Choosing between SSD and HDD
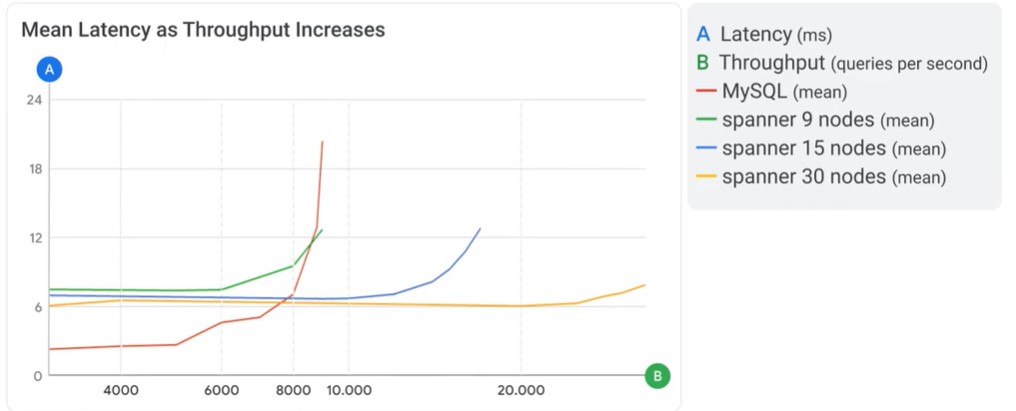
Cloud Spanner
Properties
- Globally
- Fully managed
- Relational database
- Transactional consistency
- Data in Cloud Spanner is strongly typed
- Define a schema for each database
- Schema must specify the data types of each column of each table
Important features
- Schema design, Data Model and updates
- Secondary indexes
- Timestamp bounds and Commit timestamps
- Data types
- Transactions
Datastore
Properties
- Datastore is a NoSQL object database
- Atomic transactions
- ACID support
- High availibility of reads and writes
- Massive scalability with high performance
- Flexible storage and querying of data
- Blanace of strong and eventual consistency
- Encryption at rest
- Fully managed with no plannced downtime
Important features
Building and maintaining Pipelines
Apache Beam
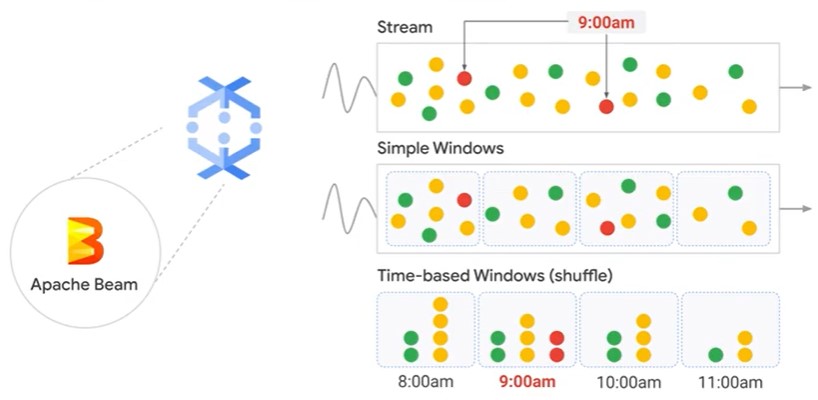
| Size | Scalability and Fault-tolerance | Programming Model | Unbound data |
|---|---|---|---|
| Autoscaling and rebalancing handles variable volumes of data and growth | On-demand and distribution of processing scales with fault tolerance | Efficient pipelines + Efficient execution | Windowing, triggering, incremental processing and out-of-order data are addressed in the streamning model. |
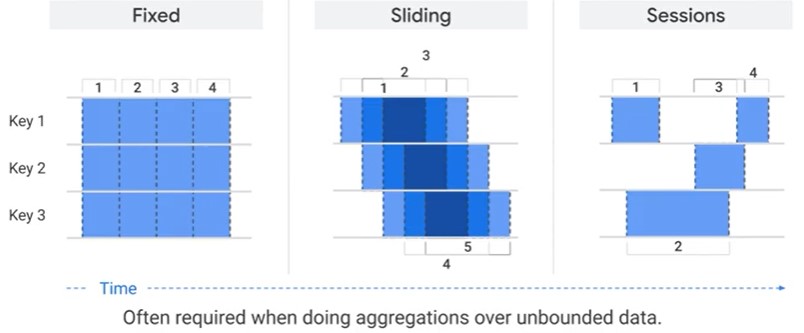
Dataflow Windowing for streams
- Triggering: controls how results are delivered to the next transforms in the pipeline.
- Watermark: is a heuristic that tracks how far behind the system is in processing data from an event time.
- Fixed, sliding and session-based windows.
- Updated results (late), or speculative results (early)
Side Inputs in Dataflow
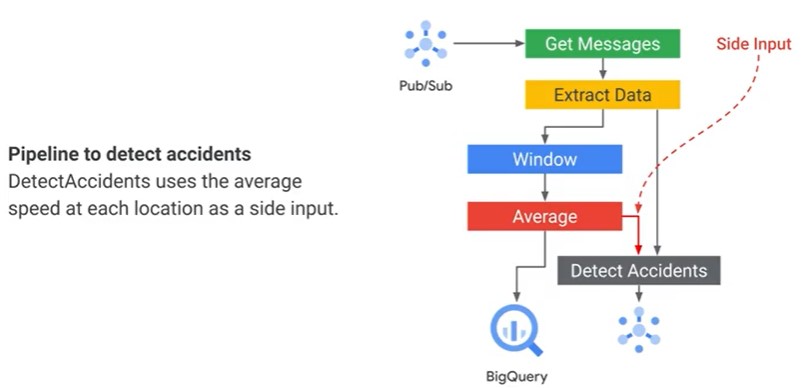
Building a Streaming Pipeline
- Stream from Pub/Sub into BigQuery. BQ can provide streaming ingest to unbounded data sets.
- BQ provides stream ingestion at a rate of 100krows/table/second
- Pub/Sub guarantees delivery, but not the order of messages.
Scaling Beyond BigQuery
| BigQuery | Cloud BigTable |
|---|---|
| Easy, Inexpensive | Low latency, High throughput |
| latency in order of seconds | 100kQPS at 6ms latency in 10 node cluster |
| 100k rows/second streaming |
Analyze Data and enable Machine Learning
Analyze Data
Pretraned Models
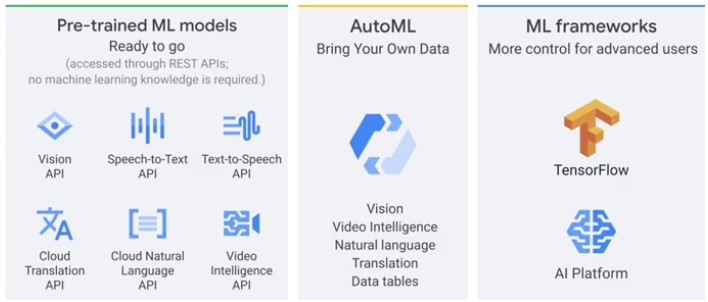
The three modes of the natural language API are: Sentiment, Entity and Syntax
Notebooks, Datalab
Cloud ML
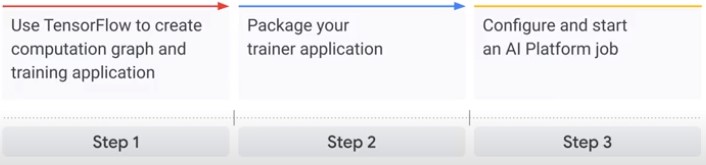
Machine Learning
| Step | Tool |
|---|---|
| Collect data | Logging API, Pub/Sub |
| Organize data | BigQuery, Dataflow, ML Preprocessing SDK |
| Create Model | Tensorflow |
| Train, Deploy | Cloud ML |
Tensorflow
High-Performance library for numerical computation. Tensorflow is coded for example in Python using DG (Directed Graphs) => Lazy evaluation (can be run in eager mode).
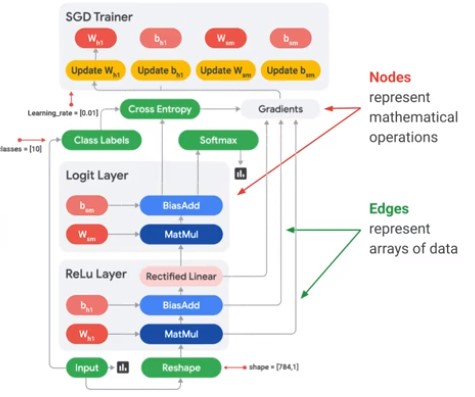
Mathematical information is transported from node to node.
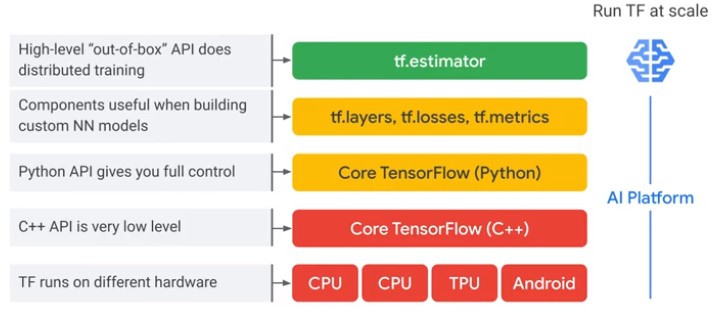
TF Methods
https://www.tensorflow.org/api_docs/python/tf/keras/losses
| Method | Description |
|---|---|
| tf.layers | A layser is a class implementing common neural networks operations, such as convolution, bat chorm, etc. These operations require managing variables, losses and updates, as well as applying TensorFlow ops to input tensors |
| tf.losses | Loss Function |
| tf.metrics | General Metrics about the TF performance |
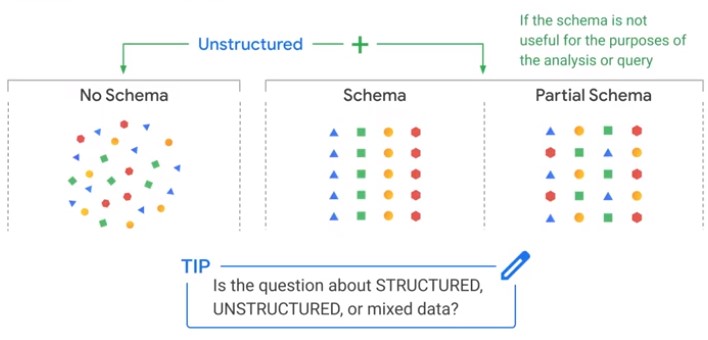
Unstructured Data
| Task | Solution |
| Real-time insight into supply chain operations. Which partner is causing issues? | Human |
| Drive product decisions. How do people really use feature x? | Human |
| Did error reates decrease after the bug fix was applied | Easy counting problems > Big Data |
| Which stores are experiencing long delays in paymemt processing | Easy counting problems > Big Data |
| Are procemmers checking in low-quality code? | Harder counting problemns > ML |
| Which stores are experiencing a lack of parking space? | Harder counting problems > ML |

Supervised Learning
Labels
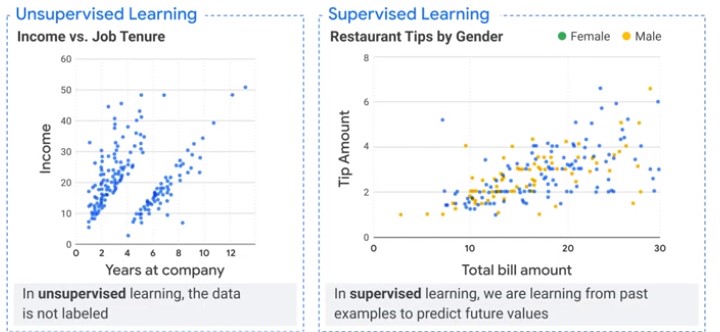
Regression, Classification
Regression and Classification models are supervised ML methods.
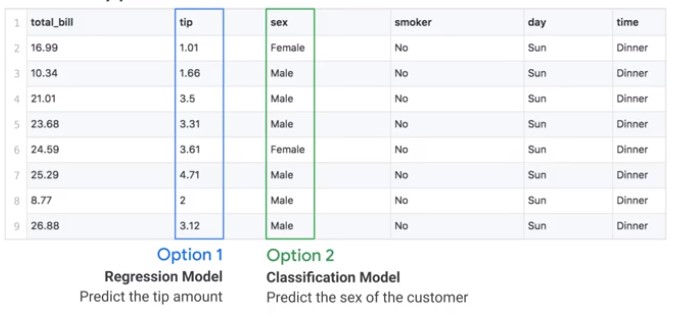
Structured data is a great source for machine learnign model, because it is already labeled.
Regression problems predict continuous values, like prices, whereas classification problems predict categorical values, like colours.
Measure Loss
Mean Squared Error (MSE)
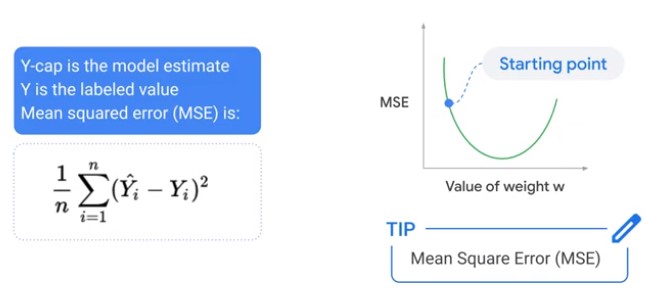 e
e
Root Mean Squared Error (RMSE)
The root of MSE. The measure is in the unit of the model and is therefore easier to interpretate.
XEntropy
Xentropy is a hint for a classification problem.
Gradient Descent

Turn ML problem into search problem.
Recompute Error after Batch of examples
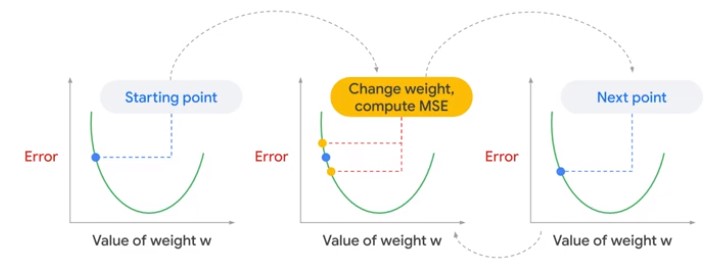
Training and Validating
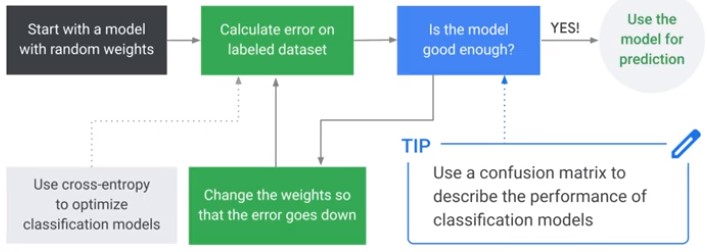
When is a Model sufficiently good?
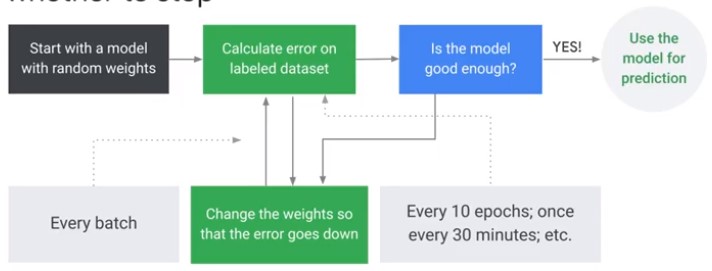
Training vs Evaluation Data
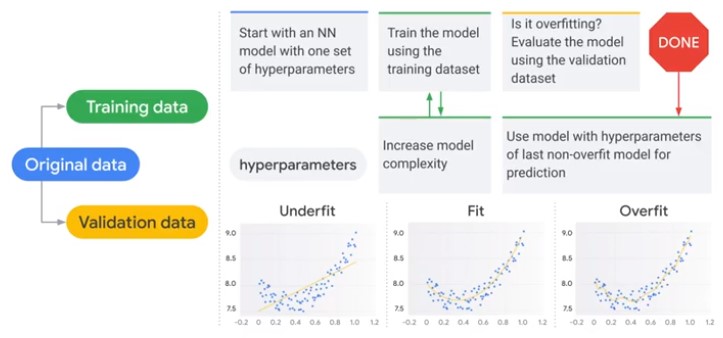
Validation Techniques
| Data | Validation |
|---|---|
| Scare | Independend Test Data, Cross Validate |
Cross Validation
Modeling Business Processes for Analysis and Optimization
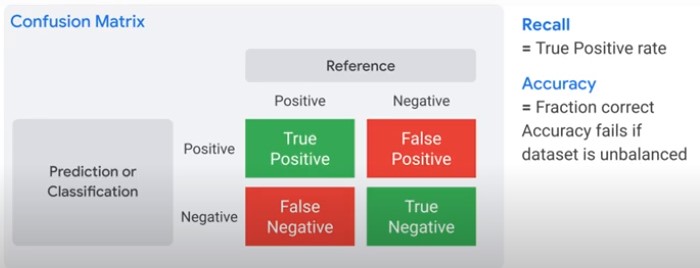
Confusion Matrix
Build, Buy od Modify > Business Priorities
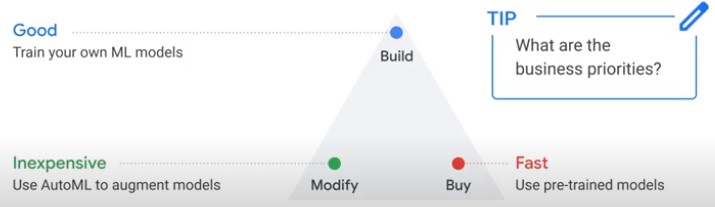
AutoML > Use an existing ML Model and tailor it to your specific needs.
Build Effective ML
Big Data > Feature Engineering > Model Architectures
Make ML Pipeline Robust
- Fault-tolerand distributed training framework
- Choose model based on validatoin dataset
- Monitor training, expecially if it will take days
- Resume training if necessary
Feature Engineering
Good features bing human insight to a problem
Choosing good features
- Is the feature you are considering related to the result you are trying to predict?
- Is the predictive value known?
- Is the feature a numeric value with meaningful magnitude?
- Are there enough examples?
Feature Engineering Process
- Pre-Processing
- Feature Creation
- Hyperparameter tuning
Other Important Concepts
- Feature crosses
- Discretize floats that are not meaningful
- Bucketize features
- Dense and sparse features
- DNNs for dense, highly correlated
- Linear for sparse, independent
Learning Rate
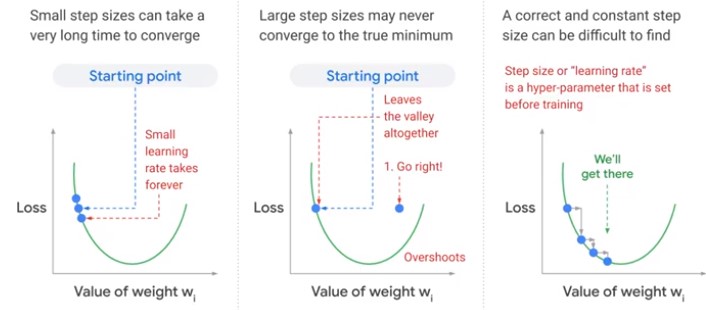
Performance
- Input data and data sources (I/O): How many bytes does your query read?
- Communication between nodes (Shuffling): How many bytes does your query pass to the next stage? How many bytes does your query pass to each slot?
- Computation: How much CPU work does your query require?
- Output (materialization): How many bytes does your query write?
- Query anti-patterns: Are your queries following SQL best practices?
Schema
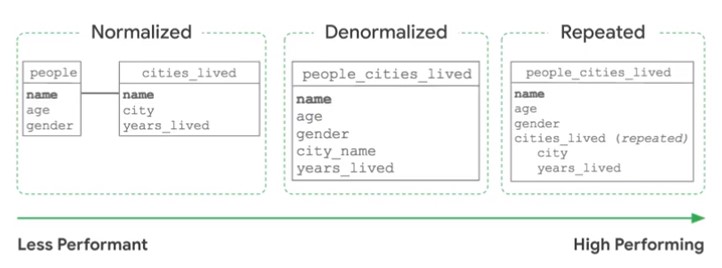
Performance (De-Normalize) vs Efficiency (Normalize).
Nested Schemas
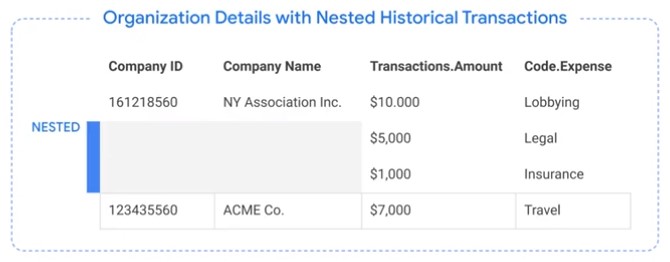
Key Elements of Performance
- I/O: How many bytes did you read?
- Do no SELECT *
- Filter using WHERE as early as possible
- Shuffle: How many bytes did you pass to next stage?
- Grouping: How many bytes do you pass to each group?
- Works best if distinct number of groups is small
- Materialization: How man bytes did you write to storage?
- CPU work: User-definded functions (UDFs), functions
- Limit UDFs to reduce computational load
Query Explamation Map

Partitioning
Time-partitioning tables are a cost-effective way to manage data. Be carfeul selecting training data from time-partitioned tables (shuffle data among time slots).
Order of Operatoins can inluence shuffling overhead
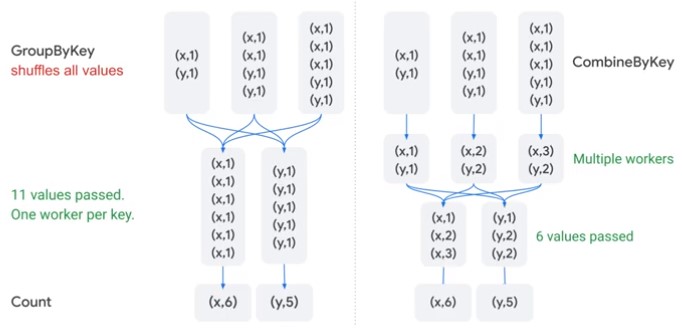
Windowing
Use windowing to manage streaming data.
Performance BigTable
Cloud BigTable spearates processing and storage.
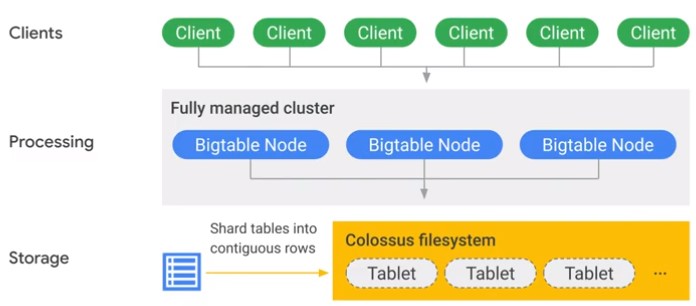
- A table can have only one Inedx
- Sparse table deign
- Looks at access patterns to improve itself by optimizing pointers
Row key Design
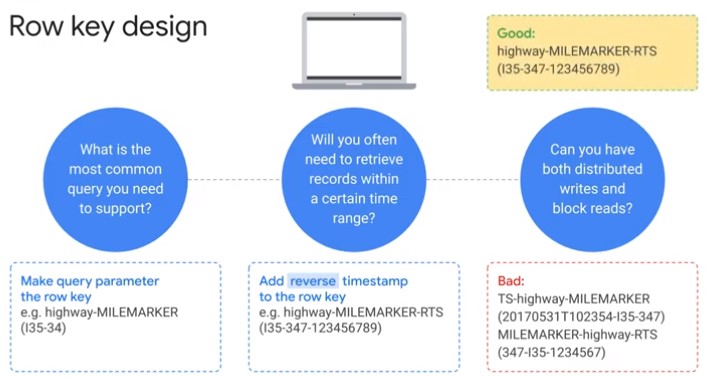
Datasets get shuffled among different tablets, which enables parallel processing.
Growing a BigTable Cluster
- Make sure clinets and Cloud Bigtable are in the same zone.
- Change schema to minimize data skew.
- Performance increses linerarly with the number of nodes.
- SSD faster than HDD
- Takes some time after scaling up nodes for performance improvement to be seen.
Pricing
| Storage | Processing | Free |
|---|---|---|
| Amount of data in table | On-demand of Flate-rate | Loading |
| Interest rate of streaming data | On-demand based on amount of data processed | Exporting |
| Automatic discount for old data | 1 TB/month free | Queries on metadata |
| Have an opt in to run high-compute queries | Cached queries | |
| Queries with errors |
Designing for Security and Complience
Privacy, Authorization and Authentication. Identity- and Accessmanagement. Intrusion detection, Attack medigationm Resililance and Recovery. Granularity of control (Table, tow, column, service).
Identity and Access
- Separate responsibilities
- Always have backup or alternative in case the responsible person is unreachable.
- Have a separate maintenance path when the normal paths aren’t working
- Use groups to allocate permissions, then separately manage group memnbership
- Customize roles for greater ganularity of permissions.
- Give each group only the permicfsions they need to preform that job or task
- Place critical functions on service machines to create accountability trail
- Backup/spare logs and records, have a review, analysis, and monitoring strategy
Cloud IAM Resource Hierarchy
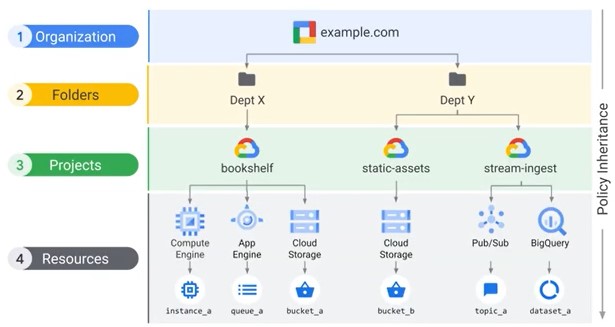
Folders
Additoinal grouping mechanism and isolation boudaries between projects
Folders allow delegation of administration rights
Encryption
| Default Encryption | Coustomer-Managed Encrytion Keys CMEK | Customer-Supplied Encyptino Keys CSK | Client-Side Encryption |
|---|---|---|---|
| Data is automatically encrypted before being written to disk | Google-generated data encryption key (DEK) is sill used | Keep kes on premises, and use them to encrypt your cloud service | Data in encrypted before it is sent to the cloud |
| Each encryption key is itself encrypted with a set of root keys | Allows you to create, use, and revoke the key encryption key (KEK) | Google cant’t recover them | Your keys; your tools |
| Uses Cloud Key Management Sevice (Cloud KMS) | Disk encryption on VMs Cloud Storage encryption | Google doesn’t know wheether your data is encrypted before it’s uploaded | |
| Keys are never stored on disk unencrypted | No way to recover keys | ||
| You provide your key at each operation, and Google purges it from its servers when each operation completes | If you loase your keys, remember to delete the objects! |
Cloud Security
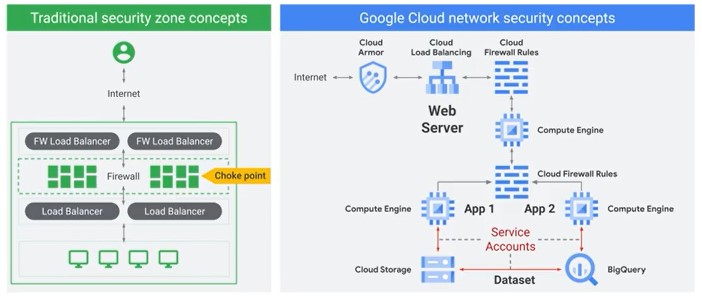
Performing Quality Control
Service specific Monitoring is available (like TensordBoard). Assessing, troubleshooting and improving data representations and improving data processing infrastracture are distributed through all the technologies. Advocating policies and publishing data and reports are not just technical skills.
Monitoring
- Available for all BigQuery customers
- Fully interactive GUI. Custom dashboards
TensorBoard
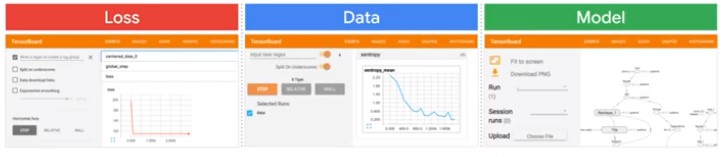
Esimator comes with a method that handles distributed training and evaluation
estimator = tf.estimator.LinearRegressor(
model_dir=output_dir,
freature_columns=feature_cols)
...
tf.estimator.train_and_evaluatre(estimator, train_spec, eval_spec)
- Distribute the graph
- Share variables
- Evaluate occasionally
- Handle machine failures
- Create checkpoint files
- Recover from failures
- Save summaries for TensorBoard
Visualize TF.
Ensure Reliability
Service produces consistent outputs and works as expected. Available vs Durable (Data loss).
Distributing for Scale may improve reliability

Data Visualization and Reporting Tools
Google Data Studio